Web scraping large websites often involves dealing with IP bans, rate limiting, and bot detection firewalls. To reduce your fingerprint and avoid getting blocked, one of the most effective tactics is IP address rotation using a proxy provider. In this guide, I will walk you through exactly how I implemented IP rotation with Smartproxy’s Datacenter Proxies in my project using selenium-wire, undetected-chromedriver, and a custom stealth browser configuration.
Table of Contents
Disclaimer
Decodo (formerly operating as Smartproxy) is a trademark or brand name owned by its respective rights holder. This blog is not affiliated with, endorsed by, or sponsored by Decodo or any of its parent or associated entities. All references to Smartproxy in this article are solely for educational purposes, to explain how proxy rotation can be configured.
This blog post is intended solely for educational purposes. It demonstrates how IP rotation works in the context of web scraping. The techniques described should not be used for violating website terms of service, scraping private or protected data, or conducting unauthorized automation. Always respect the legal and ethical guidelines of the websites you interact with.
Why Rotate IPs?
Websites often limit the number of requests from a single IP address. If you send too many requests too quickly from the same IP, you may trigger temporary bans, CAPTCHA challenges, or even IP blocking. Rotating your IP (via proxies) makes each session look like it’s coming from a different user which will help you navigate the rate limiting or blocks.
Tools and Setup
| Component | Description |
| Smartproxy | Paid proxy provider with IP pools |
| Selenium Wire | Extended Selenium to intercept requests and apply proxies |
| undetected-chromedriver | Stealth Chrome browser to bypass bot detection |
| Python | Core scripting language |
| Configuration file (.ini) | Stores Smartproxy credentials and port list |
Before You Begin: Subscribe to a Proxy Provider
In this guide, we are using Smartproxy for obtaining IP pools to use in our project. If you don’t have a Smartproxy account yet, here’s how to get started:
Step 1: Sign Up at Smartproxy
- Go to smartproxy.com
- Create an account and verify your email
Step 2: Purchase a Datacenter Proxy Plan
Usually, a datacenter proxy plan is a cost-effective option compared to residential/ISP proxies and will serve the purpose if your project does not involve large-scale scraping. However, a residential/ISP proxy has more reputation score and thus a better option for sophisticated and large-scale scraping as you will encounter less challenges compared to using datacenter proxies which are likely to have low a reputation score.
- Navigate to Dashboard → Buy Proxies
- Choose Datacenter as the proxy type
- Select a plan with location set to Australia (if targeting .au domains)
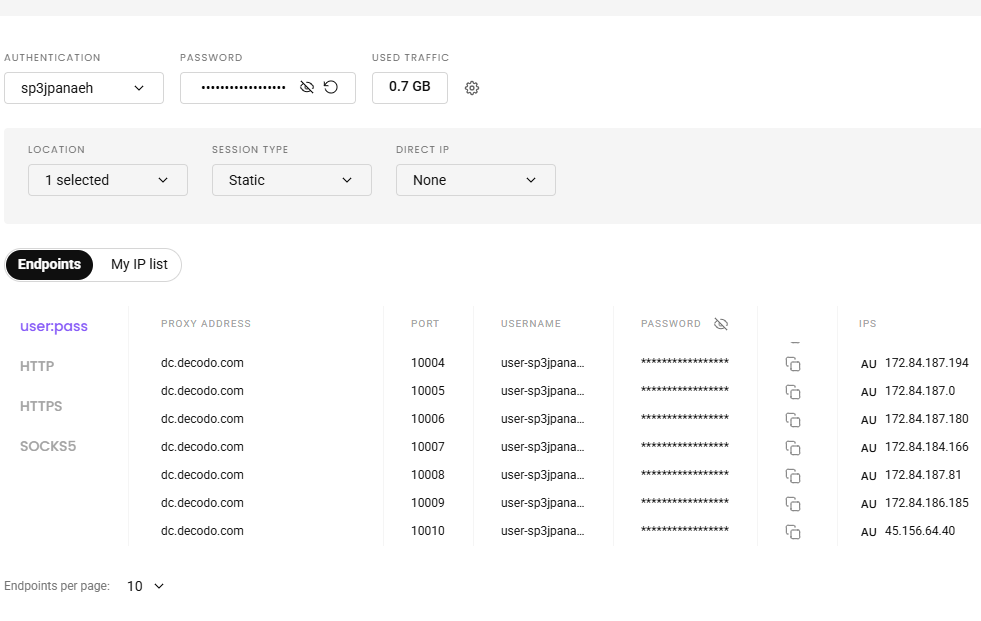
Step 3: Configure Your Proxy User
In Dashboard → Proxy Setup, select:
- Authorization type: User:Pass Auth
- Proxy Endpoint: dc.decodo.com
- Ports: e.g., 10001, 10002, etc.
Create a proxy user (e.g., yourusername-au)
8 Powerful Steps to Pair IP Address Rotation with Stealth
Rotating IPs is a key tactic to avoid getting blocked while web scraping. In this guide, we will walk through how to set up robust IP rotation using Smartproxy, Selenium Wire, and Python. You will learn how to dynamically assign proxy sessions, configure stealth browser behavior, and verify your scraper is routing traffic through rotating IPs.
- Read Proxy Credentials from Config File
[Smartproxy]
Username = your_username-au
Password = your_password
Host = dc.decodo.com
Port = 10001,10002,10003,10004These are loaded dynamically using configparser.
- Generate a Random Session + Port
session_id = random.randint(100000, 999999)
proxy_user = f"{proxy_user_base}-session-{session_id}"
proxy_port = random.choice([port.strip() for port in ports_str.split(',')])This ensures that each session uses:
- A different Smartproxy IP (via new session ID)
- A random proxy port (from your allowed pool)
- Configure Proxy in Selenium Wire
proxy_auth = f"http://{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}"
seleniumwire_options = {
'proxy': {
'http': proxy_auth,
'https': proxy_auth,
'no_proxy': 'localhost,127.0.0.1'
}
}This allows Selenium to route all browser traffic (including XHR and fetch requests) through Smartproxy.
- Set a Realistic User-Agent
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36"This mimics traffic from a real Chrome browser and reduces detection.
- Setup Stealth Chrome Options
options = uc.ChromeOptions()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument(f"--user-agent={user_agent}")
# Additional stealth arguments...- Launch the Undetected Chrome Driver
driver = uc.Chrome(
seleniumwire_options=seleniumwire_options,
options=options,
version_main=135,
use_subprocess=True
)This initializes a browser that routes all traffic through Smartproxy and uses stealth settings.
- Apply Stealth Fingerprinting
And apply fingerprint evasion using selenium-stealth:
stealth(driver,
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine"
)
driver.execute_script("delete navigator.__proto__.webdriver")This removes common fingerprint clues that websites use to detect bots.
- Verify the Proxy is Working
After the browser launches:
driver.get("https://api.ipify.org?format=text")
ip = driver.find_element(By.TAG_NAME, "body").text.strip()
print(f"Proxy IP detected: {ip}")If this returns 127.0.0.1 or localhost, the proxy failed to connect. Otherwise, you’re good to go.
Conclusion
While this setup uses datacenter proxies which are cost-effective and sufficient for many scraping tasks, they may occasionally trigger CAPTCHAs or blocks especially on sites with strong bot defenses. So, combining session-based rotation, random port selection, and browser fingerprint spoofing is essential to maintain scraping continuity. For even higher success rates and fewer interruptions, residential proxies are a great upgrade. They simulate real user behavior more convincingly but at a higher price point.
Ultimately, IP rotation is just one layer of a stealth scraping strategy. A robust web scraping logic should be combined with IP rotation, user-agent rotation, humanized delays, API-oriented scraping, and should follow ethical scraping practices not to step in legal gray zone and to contribute to the public interest and digital economy. Read the related blogs below.
- Ethical Web Scraping: 9 Smart Techniques for Responsible Automation
- Web Scraping with CAPTCHA Challenges: 3 Effective Ways to Navigate CAPTCHAs
- User-Agent Rotation Guide: 4 Techniques to Avoid Getting Blocked

Shishir Dhakal is a former Software Quality Assurance Engineer and a current postgraduate student in Information Technology Management at Deakin University, Australia. With over 3 years of industry experience, he has worked across software testing, performance engineering, and browser automation. Shishir holds a Bachelor’s degree in Information Management from Nepal and has contributed to large-scale software projects across cloud platforms and enterprise systems. Specializing in tools like Selenium, JMeter, Python, and modern QA practices with passion for quality, performance, and responsible automation, he shares practical guides and real-world insights spanning web scraping, load testing, and software engineering. Connect with him on LinkedIn or explore his technical blog for tutorials and walkthroughs.