When scraping data from websites that use sophisticated web application firewalls for content protection, user-agent rotation is a critical part of staying undetected. Without it, repeated requests from the same user-agent (UA) will flag your activity and can trigger rate-limits or even blocks. In this post, I will walk you through how to implement dynamic User-Agent rotation using Python and the fake_useragent library and apply them in Selenium-based scraping workflows including other alternative techniques.
Table of Contents
Why Rotate User-Agents?
Websites inspect the User-Agent HTTP header to determine the client making the request to make sure whether it’s a real browser, bot, or script. Rotating UAs makes your scraper appear like different real browsers (Chrome, Safari, Edge) across different OS platforms. It’s like changing your disguise every few seconds. There are multiple approaches to implement user-agent rotation depending on your tech stack and scraping setup. Below, I have demonstrated one practical method using the fake-useragent Python library and other alternative methods of generating user-agent strings.
Parse your user-agent and learn more about them here.
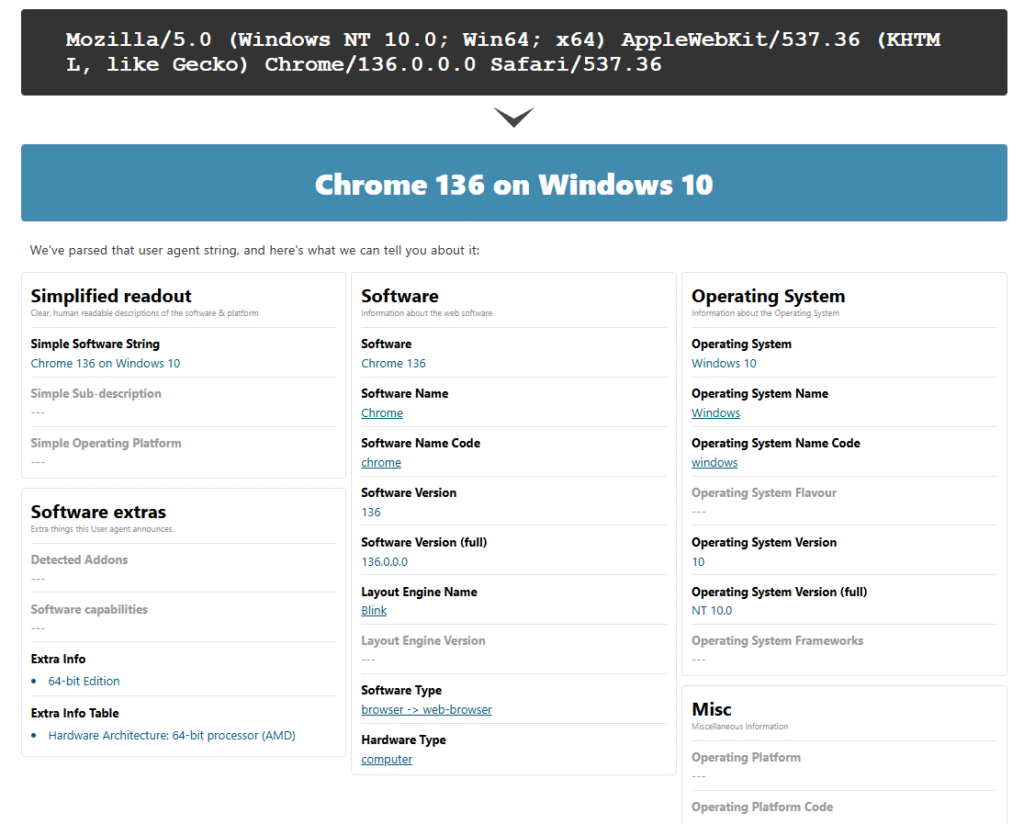
Step-by-Step: How I Implemented User-Agent Rotation in my Academic Project
One of the easiest ways to rotate user-agents in Python is by using the fake-useragent library. This helps simulate traffic from different browsers and operating systems and makes your scraping activity appear more like normal user behavior. Below is a practical example that installs the library, generates a random user-agent (with a fallback for reliability), and injects it into a Selenium session. Just make sure the generated user-agent matches your actual browser version as misalignment can be detected by modern anti-bot systems.
- Install the Library
pip install fake-useragent- Generate Random User-Agent with a Fallback
from fake_useragent import UserAgent
fallback_ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/116.0.0.0 Safari/537.36'
try:
ua = UserAgent(
browsers=['chrome', 'safari'],
os='win',
min_percentage=2.0,
fallback=fallback_ua
)
user_agent = ua.random
except Exception as e:
print(f" Failed to generate user-agent. Using fallback: {e}")
user_agent = fallback_uaImportant: The user-agent string must align with the actual browser version being automated. For instance, if your Selenium driver launches Chrome version 116, ensure your user-agent string reflects Chrome/116. Mismatched versions can be detected by advanced anti-bot tools through JavaScript APIs like navigator.userAgentData, navigator.plugins, and navigator.webdriver.
- Set User-Agent in Selenium
After generating the user-agent, we need to inject it into the options of the Selenium Web Driver.
options.add_argument(f"user-agent={user_agent}")Alternative Ways to Rotate User-Agents
- Maintain Your Own User-Agent Pool
Create a local .txt, .json, or .csv file with real user-agent strings (e.g., only Chrome 116 if your browser is Chrome 116). Example:
import random
with open('useragents_chrome_116.txt') as f:
user_agents = f.read().splitlines()
user_agent = random.choice(user_agents)- Use an API Service
You can use third party API services to obtain fresh user-agents.
- Hardcode Smart Defaults
For quick and small projects, rotate through a small hardcoded list of trusted UA strings that match your browser version:
user_agents = [
"Mozilla/5.0 ... Chrome/116 ...",
"Mozilla/5.0 ... Chrome/116 ...",
# Add more here
]
user_agent = random.choice(user_agents)Conclusion
Rotating user-agent strings is not just a best practice but it is a necessity when scraping modern websites protected by advanced bot mitigation systems. By dynamically changing your UA headers to mimic real browsers and aligning them with the actual browser version you are automating, you reduce the risk of detection and increase the longevity of your scraping sessions. These techniques are shared for educational purposes to help developers, data scientists, and researchers understand how websites work and how to test responsibly. Always respect each site’s terms of use, robots.txt, and legal guidelines when conducting automated data access.
Related Blogs
- IP Address Rotation for Web Scraping: 8 Powerful Techniques to Avoid Blocks while Scraping
- Ethical Web Scraping: 9 Smart Techniques for Responsible Automation
- Web Scraping with CAPTCHA Challenges: 3 Effective Ways to Navigate CAPTCHAs

Shishir Dhakal is a former Software Quality Assurance Engineer and a current postgraduate student in Information Technology Management at Deakin University, Australia. With over 3 years of industry experience, he has worked across software testing, performance engineering, and browser automation. Shishir holds a Bachelor’s degree in Information Management from Nepal and has contributed to large-scale software projects across cloud platforms and enterprise systems. Specializing in tools like Selenium, JMeter, Python, and modern QA practices with passion for quality, performance, and responsible automation, he shares practical guides and real-world insights spanning web scraping, load testing, and software engineering. Connect with him on LinkedIn or explore his technical blog for tutorials and walkthroughs.