An end-to-end breakdown of how I designed a web automation script to extract publicly visible product pricing data from Coles as part of my academic capstone project. The project involved automation techniques such as rotating proxies, humanized interaction patterns, API-driven data parsing, and dynamic session management that were conducted within the boundaries of standard browser-visible interactions and ethical scraping practices.
Table of Contents
Disclaimer
This article is for educational purposes only and reflects my academic work as part of a university capstone project. All data accessed was publicly visible in the browser; no login-only or private systems were involved. As per Coles’ Terms (Dec 2024), pricing data is not classified as intellectual property, and no content such as copyrighted text, logos, or images was used. No data was shared, sold, or used commercially. Coles Group Limited is not affiliated with or endorsing this content.
Coles is a registered trademark of Coles Group Limited. This blog is independently written and is not affiliated with or endorsed by Coles Group Limited.
API-based Scraping for Stability
Instead of relying on traditional HTML scraping, which can be fragile due to frequent UI changes, this project uses the browser-visible APIs which are used by the retailer’s frontend. These APIs returned structured JSON responses which made data extraction more efficient and accurate. While not publicly documented, they are observable through standard browser network activity.
A key element in constructing valid API requests was the build_id, which is a dynamic value embedded within a <script> tag with the ID NEXT_DATA, which was parsed using JavaScript within the browser.
Here’s the overall flow:
- Launch a browser using Selenium Wire + undetected_chromedriver configured with rotating proxies via Smartproxy.
- Set location cookies and store ID to simulate a typical user selecting a click-and-collect store.
- Identify and retrieve the build_id value from a structured JSON blob embedded in the homepage HTML.
- Use the category discovery API (visible in browser network traffic) to programmatically list available product categories.
- Iterate through each category’s paginated API responses to extract publicly visible product pricing data fields such as name, price, promotion, and unit size.
Tools I Used to Create the Coles Web Scraper Script
Building a robust and reliable web automation script required more than just writing code. It involved selecting the right tools to support respectful automation, maintain modularity, and ensure data consistency. Below is the tech stack that supported the automation used for this project.
| Tool | Purpose |
| Selenium Wire + undetected_chromedriver | Simulates real browser and captures network traffic |
| Smartproxy (Datacenter) | Rotates IPs per session using session ID |
| Selenium Stealth | Simulates standard user environments |
| MongoDB | Stores scraped data in a structured format |
Python Libraries (requests, random, configparser, etc.) | Control timing, logic, config loading |
All configurations like proxy credentials and category mappings were managed through external config files to keep the script modular and reusable.
Handling Bot Detection Responsibly
Modern websites often employ sophisticated web application firewalls (WAFs) to detect automated access and protect user experience. To ensure responsible and non-intrusive automation for this academic project, I used techniques such as proxy rotation and human-like interaction patterns to simulate standard browsing behavior.
Proxy Rotation: Each session used a randomly generated session ID and a different Smartproxy port to reduce the likelihood of repeated IP detection and maintain distributed request behavior.
User-Agent: The script used modern, real-world browser user-agent strings (e.g., Chrome) to reflect typical user configurations.
Browser Fingerprint Adaptation: JavaScript-accessible properties such as navigator.vendor, WebGLRenderer, and navigator.webdriver were adjusted to align with common user environments and reduce detection by bot heuristics.
Randomized Window Size: Different screen dimensions were used across sessions to avoid uniform patterns and better emulate varied device access.
Human-Like Timing: Randomized pauses and delays were introduced between actions to replicate natural browsing behavior and reduce automation footprints.
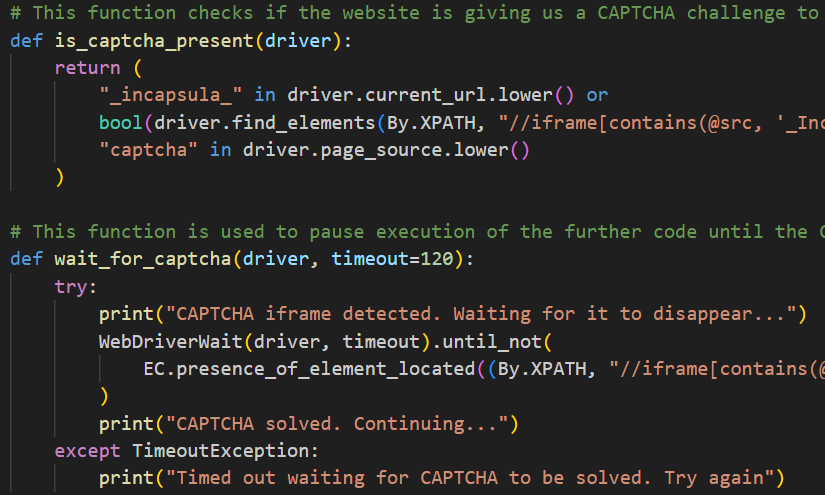
CAPTCHA Handling: If a CAPTCHA challenge was encountered, the script paused for manual resolution before continuing.
Utilizing Publicly Visible APIs for Data Extraction
Instead of navigating individual product pages, this approach utilized frontend-facing APIs observable through browser developer tools, which returned structured JSON data. This method offered a more stable and efficient way to extract information, independent of visual interface changes.
- It first discovered available categories by parsing the product browse endpoint.
- Then, it paginated through each category’s data until no further results were available.
- All responses were in clean JSON format which made the data straightforward to interpret and organize.
- Cookies and headers were maintained throughout each session to simulate a consistent browsing experience.
Category Discovery API
To identify available product categories for a particular click and collect store, the script accessed a browser-visible API endpoint responsible for populating the category listings on the website’s browse page. This API returned a JSON structure that included top-level category names, SEO tokens, and product counts.
Store, Location, and Click and Collect Method are set as:-
fulfillment_store_id = config.get('Coles', 'FulfillmentStoreId', fallback='0357')
session.cookies.set("fulfillmentStoreId", fulfillment_store_id, domain=".coles.com.au")
session.cookies.set("shopping-method", "clickAndCollect", domain=".coles.com.au")https://www.coles.com.au/_next/data/{build_id}/en/browse.jsonPurpose:
Used to extract main product categories (Level 1 menus like Bakery, Meat, Frozen, etc.) and their slugs.
Example Response Structure:
{
"pageProps": {
"allProductCategories": {
"catalogGroupView": [
{
"level": 1,
"type": "CATALOG",
"name": "Bakery",
"seoToken": "bakery",
"productCount": 120
}
]
}
}
}Filtering Logic:
Only categories where:
- level == 1
- type == “CATALOG”
- productCount > 0
are considered valid for scraping.
Code Snippet:
categories = {}
for cat in data.get("pageProps", {}).get("allProductCategories", {}).get("catalogGroupView", []):
if cat.get("level") == 1 and cat.get("type") == "CATALOG" and cat.get("productCount", 0) > 0:
categories[cat["name"]] = cat["seoToken"]Product Listing API (per category)
The website’s frontend relies on a paginated JSON data feed to deliver product listings dynamically. This feed functions similarly to a RESTful API and powers the client-side product display. The responses are tailored based on location-specific parameters, such as the selected store ID and click-and-collect preferences, which are passed via cookies during typical user interaction.
Endpoint:
https://www.coles.com.au/_next/data/{build_id}/en/browse/{category}.json?page={page}&slug={category}Purpose:
Used to fetch product listings for a given category and page number.
Pagination:
Start with page = 1 and keep increasing until no products are returned.
Example Response Structure:
{
"pageProps": {
"searchResults": {
"results": [
{
"_type": "PRODUCT",
"id": "123456",
"name": "Coles Full Cream Milk 2L",
"pricing": {
"now": 3.10,
"was": 3.50,
"comparable": 1.55
},
"merchandiseHeir": {
"category": "Dairy"
}
}
]
}
}
}Parsing Logic:
Only items with _type == “PRODUCT” are processed
Extract fields like:
- id, name
- pricing.now, pricing.was, pricing.comparable
- category from merchandiseHeir
Code Snippet:
for item in results:
if item.get("_type") != "PRODUCT":
continue
pricing = item.get("pricing", {})
merchandise = item.get("merchandiseHeir", {})
extracted.append({
"product_code": item.get("id"),
"item_name": item.get("name"),
"best_price": pricing.get("now"),
"item_price": pricing.get("was"),
"unit_price": pricing.get("comparable"),
"category": merchandise.get("category", "Unknown")
})Where the build_id Comes From
Both APIs rely on a build_id, a dynamic identifier used by the website’s frontend framework to manage route versions. This value was retrieved by parsing a structured JSON object embedded in the HTML, commonly found within a <script> tag identified as __NEXT_DATA__ :
Code Snippet:
json_data = driver.execute_script("return document.getElementById('__NEXT_DATA__').textContent;")
build_id = json.loads(json_data).get("buildId")If the build_id is missing or its format changes, the data extraction process will not function correctly. To maintain reliability, the script retrieves this value dynamically at runtime during each session.
Data Format and Structuring the Output
Once the data was extracted through API calls it was organized into a clean and analyzable format before storing it in MongoDB. Each product entry captured the following fields:
- Product name
- Current and previous prices
- Unit size and comparable pricing
Final Notes and Conclusion
While the automation script functioned effectively and was able to extract publicly visible pricing information across various product categories, occasional manual CAPTCHA input was required – particularly at the beginning of a session or when switching IPs using datacenter proxies. In contrast, running the same script with residential ISP proxies (despite their higher cost) resulted in no CAPTCHA prompts.
Overall, this project extended far beyond simple data extraction. It was an exercise in responsible automation, careful interaction with detection systems, and deeper exploration of modern web architectures. From understanding session management and load distribution to observing how web application firewalls operate, this work brought together a range of advanced concepts in web automation.
Want to go deeper? Check out these related guides:
- Ethical Web Scraping: 9 Smart Techniques for Responsible Automation
- IP Address Rotation for Web Scraping: 8 Powerful Techniques to Avoid Blocks while Scraping
- User-Agent Rotation Guide: 4 Techniques to Avoid Getting Blocked
- Web Scraping with CAPTCHA Challenges: 3 Effective Ways to Navigate CAPTCHAs
Note: All data was stored locally for private academic analysis and **not published, redistributed, or monetized**.
This article reflects personal technical exploration and does not endorse or promote unauthorized scraping. All findings are based on browser-visible network-activity as of 6 June, 2025 without breaching authentication or protected systems. All activities:
- Respected the website’s robots.txt directives
- Did not access login-only areas or secured APIs
- Used visible client-side traffic only
- Did not overload, flood or harm any server
- Never redistributed or commercialized collected data
In accordance with Australian laws, particularly the *Copyright Act 1968 (Cth)* and *Criminal Code Act 1995 (Division 477)*, no unauthorized access, circumvention, or distribution of protected material occurred.

Shishir Dhakal is a former Software Quality Assurance Engineer and a current postgraduate student in Information Technology Management at Deakin University, Australia. With over 3 years of industry experience, he has worked across software testing, performance engineering, and browser automation. Shishir holds a Bachelor’s degree in Information Management from Nepal and has contributed to large-scale software projects across cloud platforms and enterprise systems. Specializing in tools like Selenium, JMeter, Python, and modern QA practices with passion for quality, performance, and responsible automation, he shares practical guides and real-world insights spanning web scraping, load testing, and software engineering. Connect with him on LinkedIn or explore his technical blog for tutorials and walkthroughs.